Foreword
I’ve been meaning to write this blog post for a long time. I had the idea sometime in September 2020, and started doing a bit of lit review. Sometime around Christmas that year, I was going to finally sit down and write the blog post but I quickly realized that even after all the literature review I did, it was significantly more nuanced than I had anticipated.
How nuanced specifically? Well I threw away all of my work four times, and brought the time frame of writing down all my thoughts from a few weeks to over 2 – 3 years.
This blog post discusses the first two papers in a series. Towards a Formal Model of Narratives, published at WNU2021 and Fabula Entropy Indexing: Objective Measures of Story Coherence, also published at WNU2021.
I use the word narrator to refer to a realization of an author. I will assume basic model theory, but the paper this post is covering explains it in more detail. Work cited for this post can be found in the two papers above, particularly the first one.
Introduction
Let’s start with a simple story.
- John wanted apples.
- John went to the store to buy apples.
- The store informed John they had no apples.
- John was sad.
In this story our protagonist, John, is craving apples. He has the intent to purchase apples but is unhappy that the store he goes to has no apples. This is my intent, as the narrator. You as the reader could have read the story differently. Lets exclude grammatical nuance (e.g. that you assumed John went to the Apple Store, rather than a grocer).
Let’s also for a moment assume you received this story all at once. You did not stop to think about the story between statements made. You could, under a reasonable set of constraints, interpret this story that John was not sad that the store did not have apples- rather he was sad that he had to go to the store or that the store manager spoke poorly to John.
Basic Commutative Structure
These are both entirely valid interpretations. We refer to such an interpretation as a Possible World. They are in the most literal sense a realization of a reasoner’s internal world model.
The reader and narrator can have entirely different internal models. In fact, it is inconceivable for a narrator and reader to have identical internal models- no two humans share an identical set of experiences and therefore do not share an identical set of models. All pairs of narrators and readers have different models besides degenerate cases.
So from the top. I, as an author, query my internal world model. By writing the story down and restricting the point of view, I create the narrator’s model and story. This story is then conveyed to you, the reader. You, being the intelligent reader you are, create a world model that agrees with both the story and your internal world model.
We can express this directly in the following commutative diagram.

Where Fabula here refers to some claims, typically in a graphical representation, about a particular story world. Discourse refers to conveying the fabula through some medium, whether it be writing a story or giving an oral presentation.
Time
Up until now all of our representations have not utilized a notion of time. They assume specifically that the discourse is given all at once. Of course this is not an accurate model of what is going on, in many mediums the narrator would know where the story should be going before the reader has a chance to digest.
If we allow the narrative to evolve over time, that is to say the narrator can expand their fabula while the reader aims to take this new information and both compress and expand their set of possible worlds then we can arrive at the following commutative diagram.

Here 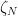

In this regard, elaborating on above, 
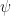
Let’s say for instance that we as the narrator introduce the proposition that “John was sad.” This in turn expands 

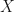
A bit of background
Let’s say that our reader had N possible worlds, each with a minimum hamming distance of 1 in the set of N-1 possible worlds. That is to say, for every possible world, there exists another possible world that only differs by a single constant/function/relationship.
We can then conceivably organize our possible worlds into a tree structure. The root node refers to a notion of a maximal possible world. We’ll refer to this possible world as 
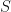
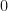


We refer to an Ultrafilter, denoted 
Ultrafilters are incredibly powerful- and actually kind of too powerful for this use case. We can describe a slightly different structure, called an Ultraproduct which is a structure described over a set of ultrafilters. Given a component of a model, every ultrafilter can cast a vote as to whether or not it holds within its possible worlds. For some notion of “majority,” which would be too difficult to completely define at this high level of abstraction, we can say a constant/relationship/function is contained in an ultraproduct 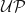
This notion of majority allows us define something similar to “non-zero measure” without having a notion of measure. The number of ultrafilters we can construct are inherently infinite, in fact if they are finite none of this works.
What does this give us?
As discussed, a common notion in modal logic is to view the structure of possible worlds as an ultrafilter. The primary benefit of this does not actually come from the ultrafilters, it comes from the ultraproducts. By taking an infinite set of possible worlds we can construct effectively a ground truth by only considering propositions that are true in the majority of possible worlds. One can think of this ground truth as the most likely world that the reader is considering.
Similarly, given the above, ultraproducts and ultrafilters allow for no notion of measure. They exist for sets of objects like this which do not have a notion of probability associated with them. Said being, we can fairly easily replace them with measure if we want to be slightly less formal. The notion of ground truth story world refers to the story world who’s generator is the maximal set of constants a reader would write down if we could probe their inner thoughts directly. I hesitate to say if a reader is pressed, allowing the reader to think more deeply about their story world representation might alter the representation itself.
By using this notion of majority, we can measure how the possible worlds of a varying set of readers differ. Controlling for external factors we could theoretically ask a sufficiently large set of questions such that if intent was conveyed properly by the author then most majority possible worlds should agree.
This brings us to the notion of EWC and ETC. EWC refers to time invariant coherence, Entropy of World Coherence, in which we measure if transition irrelevant facts about the world remain consistent between possible worlds.
By comparison, ETC, Entropy of Transitional Coherence, ask about the reader’s transition model. The more consistent these transitions are between readers then the more likely the author properly conveyed the rules that govern their world.

Do these metrics even work?
They do! In the second paper linked above, which by the way I might add gives an extremely gentle and non-overly rigorous introduction to this material, shows that not only is it a strong signal, it is also very robust.
In Fabula Entropy Indexing: Objective Measures of Story Coherence my coauthors and I look to artificially corrupt stories and measure the impact to EWC and ETC. We found that not only is the margin significant, but EWC and ETC can act as a strong metric to evaluate creative NLG models.


Plotto stories are generated by constructing a causal graph of 5 major plot points, each one is expanded using a formally described L-grammar. To corrupt stories for testing ETC, we shuffled the order of major plot points, thus disrupting order of our causal graph. This means that the transitions should register in the reader’s mind as noncoherent.
The non-plotto dataset refers to a collection of short stories by famous authors, ranging from 5 – 10 sentences. Once again, more details can be found in the paper. We corrupted these by negating random adjectives in the story. The signal is not as strong for EWC. More research is needed to determine why.
Conclusion and Future Work
I am extremely grateful for how far this work has come in such a short time. There is mountains of work to do. For instance, all of this work assumes that the narrator is a perfect realization of the author. Namely that the narrator cannot be deceptive or lie to the reader- we don’t allow for suspense or plot twists. We plan to fix that in a follow up sometime in the fall.
Other work that needs to be done is methods to evaluate not only the story but the reader model or narrator model. Can for instance GPT3 write not only a coherent story but a coherent narrator as well? This has yet to be shown. More research is needed.
